
Dẫu các robot đã ngày một tiên tiến hơn theo thời gian, phần lớn chúng vẫn còn không có khả năng định vị một cách tự tin trong những không gian có nhiều vật thể, như các khu vực công cộng hay đường xá trong các môi trường đô thị. Để thực hiện điều đó ở quy mô lớn và trong các thành phố thông minh trong tương lai, các robot sẽ cần có khả năng định vị một cách tự tin và an toàn trong các môi trường đó mà không va chạm với con người hoặc các vật thể ở gần.
Một ví dụ về robot chuyển động trong môi trường đa vật thể có chuyển động.

Các nhà khoa học tại trường đại học Zaragoza và Viện nghiên cứu Kỹ thuật Aragon ở Tây Ban Nha mới đây đề xuất một cách tiếp cận dựa trên học máy có thể giúp cải thiện sự định vị của robot ở cả môi trường đông đúc trong nhà và ngoài trời. Cách tiếp cận này, mới được giới thiệu ở dạng tiền ấn phẩm trên kho lưu trữ arXiv, nêu chi tiết về việc sử dụng các điểm thưởng nội tại, vốn là “điểm thưởng” cốt yếu mà một tác tử AI nhận được khi thực hiện các hành vi không liên quan nhiều đến nhiệm vụ nhưng vẫn cố hoàn thành 1.
“Sự định vị tự động hóa của robot là một vấn đề mở chưa được giải quyết, cụ thể trong các môi trường phi cấu trúc và chuyển động, nơi một robot phải tránh va chamh với các vật cản chuyển động và chạm đến đích”, Diego Martinez Baselga, một trong những nhà khoa học thực hiện nghiên cứu này, nói với Tech Xplore. “Các thuật toán học tăng cường sâu đã chứng minh có thể có được hiệu suất cao theo nghĩa tăng tỉ lệ thành công và rút ngắn thời gian về đích nhưng vẫn còn cần phải cải thiện nhiều”.
Phương pháp này do Martinez Baselga và cộng sự của mình phát triển dựa trên việc sử dụng điểm thưởng nội tại, điểm thưởng được thiết kế để gia tăng chuyển động của tác tử trong khám phá ra “các trạng thái’ mới (ví dụ các tương tác với môi trường) hoặc giảm thiểu mức độ bất định của một kịch bản cho trước vì vậy các tác tử có thể dự đoán tốt hơn các hệ quả có thể xảy ra với việc thực hiện hành động chúng. Trong bối cảnh nghiên cứu của mình, các nhà nghiên cứu đã sử dụng các điểm thưởng để khuyến khích các robot di chuyển đến những khu vực chưa biết trong môi trường hoạt động và khám phá môi trường ấy theo những cách khác nhau, vì vậy mà nó có thể học hỏi để định vị hiệu quả hơn theo thời gian.
“Phần lớn công việc của học tăng cường sâu cho định vị trong không gian đa vật thể của việc tập trung một cách tiên tiến nhất vào việc cải thiện các mạng lưới và quá trình xử lý các giác quan của robot”, Martinez Baselga nói. “Cách tiếp cận của tôi là nghiên cứu cách khám phá môi trường trong suốt quá trình tập luyện để cải thiện quá trình học hỏi. Trong huấn luyện, thay vì cố gắng hành động một cách ngẫu nhiên hoặc tối ưu những hành động khác, robot cố gắng làm theo những gì mà nó cho là có thể học hỏi được nhiều hơn từ đó”.
Một quỹ đạo có va chạm của robot được tập huấn sử dụng một chiến lược khám phá (trái) và một quỹ đạo thành công của một robot được huấn luyện với điểm thưởng nội tại trong cùng kịch bản. Nguồn: Martinez-Baselga, Riazuelo & Montano
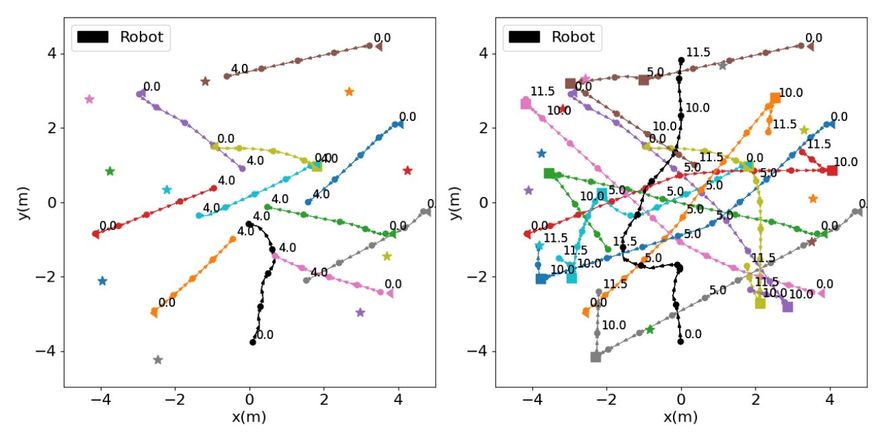
Martinez Baselga và đồng nghiệp của mình đã đánh giá tiềm năng sử dụng điểm thưởng nội tại để giải quyết vấn đề định vị của robot trong các không gian có nhiều vật thể bằng việc sử dụng hai cách tiếp cận gần nhau. Thứ nhất là sự tích hợp cái gọi là “mô đun tò mò nội tại “ (ICM), trong khi cái thứ hai dựa trên cơ sở một loạt thuật toán mà người ta gọi là các mã hóa ngẫu nhiên cho khám phá hiệu quả (RE3).
Các nhà nghiên cứu đánh giá các mô hình này trong một loạt mô phỏng, được chạy trên mô phỏng CrowdNav. Họ phát hiện ra là cả hai cách tiếp cận mà mình đề xuất tích hợp điểm thưởng nội tại đều vượt trội hơn những phương pháp tiên tiến đã được phát triển trước đây cho định vị của robot trong các môi trường có nhiều vật thể.
Trong tương lai, nghiên cứu này có thể sẽ khuyến khích các nhà nghiên cứu robot khác sử dụng điểm thưởng nội tại khi huấn luyện các robot của mình, để cải thiện năng lực của chúng để thực thi nhiệm trong trong những trường hợp chưa được dự đoán trước và chuyển động an toàn trong những môi trường có chuyển động. Thêm vào đó, hai mô hình dựa trên điểm thưởng nội tại được Martinez Baselga và đồng nghiệp thử nghiệm có thể nhanh chóng được tích hợp với các robot thật để đánh giá tiềm năng của chúng.
“Các kết quả cho thấy là việc áp dụng những chiến lược khám phá thông minh khiến robot học hỏi nhanh hơn và học được ra quyết định cuối cùng tốt hơn; và chúng có thể được ứng dụng vào các thuật toán tồn tại để cải thiện các thuật toán đó”, Martinez Baselga cho biết thêm. “Trong nghiên cứu tiếp theo của tôi, tôi dự kiến cải thiện học tăng cường sâu trong định vị của robot để khiến nó an toàn hơn và tin cậy hơn. Đây là điều quan trọng để sử dụng chúng trong thế giới thật”.
Thanh Hương tổng hợp
Nguồn : https://techxplore.com/news/2023-02-approach-robot-crowded-environments.html
https://www.analyticsinsight.net/making-robots-more-independent-by-using-humans-as-sensors/




Top comments (0)