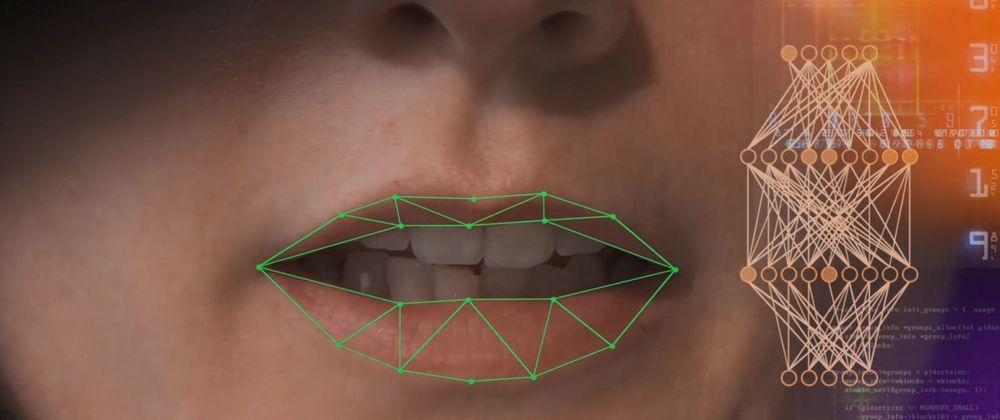
Trong những năm gần gây, các kỹ thuật học sâu đã đạt được những tiến bộ đáng chú ý trong nhiều tác vụ xử lý ngôn ngữ và hình ảnh. Những tiến bộ này bao gồm việc nhận dạng tiếng nói bằng hình ảnh (VSR) – một tác vụ đòi hỏi phải xác định được nội dung của lời nói chỉ bằng cách phân tích chuyển động môi.
Ảnh: analyticsindiamag.com
Mặc dù một số thuật toán học sâu để thực hiện tác vụ VSR này đã đạt được những kết quá rất hứa hẹn, tuy nhiên, chúng hầu như chỉ được huấn luyện để nhận dạng tiếng nói tiếng Anh, do hầu hết các bộ dữ liệu huấn luyện hiện nay không có các tiếng nói của các ngôn ngữ khác. Điều này khiến cho lượng người dùng tiềm năng của thuật toán bị giới hạn ở nhóm người sống hoặc làm việc ở môi trường nói tiếng Anh.
Mới đây, các nhà nghiên cứu tại Đại học Hoàng gia Luân Đôn đã phát triển một mô hình có thể thực hiện nhiệm vụ VSR với nhiều ngôn ngữ khác nhau. Trong bài báo mới được công bố trên tạp chí Nature Machine Intelligence, các tác giả đã cho thấy mô hình mới vượt trội hơn so với một số mô hình trước đây (dù các mô hình trước được huấn luyện trên những bộ dữ liệu lớn hơn nhiều).
“Trong quá trình làm luận án tiến sĩ, tôi đã nghiên cứu một số chủ đề, chẳng hạn như cách kết hợp thông tin hình ảnh với âm thanh để nhận dạng tiếng nói, cũng như cách nhận dạng tiếng nói bằng hình ảnh một cách độc lập với tư thế đầu của người tham gia. Và tôi nhận ra rằng phần lớn các tài liệu đã có chỉ xử lý tiếng nói tiếng Anh mà thôi”, Pingchuan Ma – người nhận bằng tiến sĩ ở Đại học Hoàng gia và là tác giả chính của bài báo – cho biết.
Do đó, nghiên cứu của Ma và đồng nghiệp đặt mục tiêu huấn luyện một mô hình học sâu có khả năng nhận dạng tiếng nói trong nhiều ngôn ngữ khác nhau từ chuyển động môi của người nói, sau đó so sánh hiệu quả của mô hình mới này với các mô hình vốn được huấn luyện để nhận dạng tiếng nói tiếng Anh. Theo các tác giả, mô hình mới cũng giống như mô hình do các nhóm nghiên cứu khác giới thiệu trước đây, tuy nhiên điểm khác biệt nằm ở chỗ mô hình mới đã tối ưu hóa một số siêu tham số, đồng thời tăng cường bộ dữ liệu (bằng cách thêm các phiên bản dữ liệu tổng hợp, được sửa đổi một chút) và sử dụng thêm hàm mất mát (loss functions).
“Nghiên cứu của chúng tôi đã cho thấy có thể sử dụng các mô hình tương tự để huấn luyện các mô hình VSR với các ngôn ngữ khác”, Ma giải thích. “Mô hình của chúng tôi lấy hình ảnh thô làm dữ liệu đầu vào mà không trích xuất bất kỳ đặc điểm nào, sau đó mới tự động tìm hiểu những đặc điểm hữu ích cần trích xuất từ những hình ảnh này để hoàn thành các tác vụ VSR”.
Trong các đánh giá ban đầu, mô hình mới của nhóm hoạt động rất tốt, vượt trội so với các mô hình VSR khác vốn được huấn luyện trên những tập dữ liệu lớn hơn rất nhiều. Tuy nhiên, đúng như dự đoán, mô hình này hoạt động kém hiệu quả hơn so với các mô hình nhận dạng tiếng nói tiếng Anh, chủ yếu là do các tập dữ liệu sẵn có để huấn luyện ít hơn so với dữ liệu tiếng Anh.
Ma và các đồng nghiệp của ông đã chỉ ra rằng, việc thiết kế cẩn trọng các mô hình học sâu có thể giúp cho mô hình này đạt được hiệu quả cao nhất trong các tác vụ VSR, thay vì chỉ đơn giản là sử dụng các phiên bản mô hình lớn hơn hoặc thu thập nhiều dữ liệu huấn luyện hơn. Điều này có thể dẫn đến sự thay đổi trong hướng nghiên cứu để cải thiện các mô hình VSR tương lai.
“Một trong những lĩnh vực nghiên cứu chính mà tôi quan tâm là cách kết hợp các mô hình VSR với tính năng nhận dạng giọng nói (chỉ dựa trên âm thanh) hiện nay”, Ma nói thêm. “Tôi đặc biệt quan tâm đến việc làm thế nào để mô hình có thể hiểu chúng nên dựa vào mô hình nào tùy thuộc vào điều kiện tiếng ồn. Nói cách khác, trong môi trường ồn ào, mô hình nghe – nhìn nên dựa nhiều hơn vào thông tin hình ảnh. Ngược lại, khi vùng miệng của người nói bị che khuất thì mô hình này cần phụ thuộc nhiều hơn vào âm thanh. Tuy nhiên, các mô hình hiện nay về cơ bản là bị ‘đóng băng’ sau khi được huấn luyện và không thể thích ứng với những thay đổi trong môi trường như vậy”.□
Mỹ Hạnh lược dịch
Nguồn: https://techxplore.com/news/2022-11-speech-languages-speaker-lip-movements.html






Latest comments (0)